Outperforming human experts at AI R&D
Published
A Preview of Locus on AI R&D
TL;DR — Locus sustains improvement over days and now exceeds human experts on RE‑Bench at equal time and compute. It sets SOTA on KernelBench and MLE‑Bench Lite, demonstrating the potential of scaling test-time search for scientific discovery.
Earlier this year, we introduced Zochi, the first Artificial Scientist to pass peer review and publish a paper at a CORE A*-ranked venue (ACL 2025 Main). Today we’re sharing preliminary results for Locus, a long-horizon, Artificial Scientist system that achieves superhuman performance at AI R&D on RE-Bench and sets state-of-the-art results on KernelBench and MLE-Bench Lite.
These benchmarks assess the ability of automated systems to perform real frontier AI R&D tasks across various domains. On RE-Bench, Locus is the first system to surpass human researchers when given the same amount of time and computational resources. Notably, Locus is a general-purpose system that outperforms many specialized systems designed specifically for these benchmarks.
Locus is a natural progression from Zochi and builds on our work in scaling test-time search and improving open-ended scientific reasoning. Unlike previous AI systems that plateau after a few hours, Locus maintains consistent performance improvement up to several days by orchestrating thousands of experiments simultaneously. This massive parallelization enables a new type of scientific process, one that facilitates structured long-horizon exploration of unsolved problems. The ability to sustain progress over multiple days opens up possibilities we're excited to pursue: we imagine deploying Locus on week or month-long runs to tackle the most difficult challenges in computational sciences.
Capabilities
We tested Locus on three benchmarks designed to measure its ability to perform frontier AI research and engineering tasks across a variety of domains.
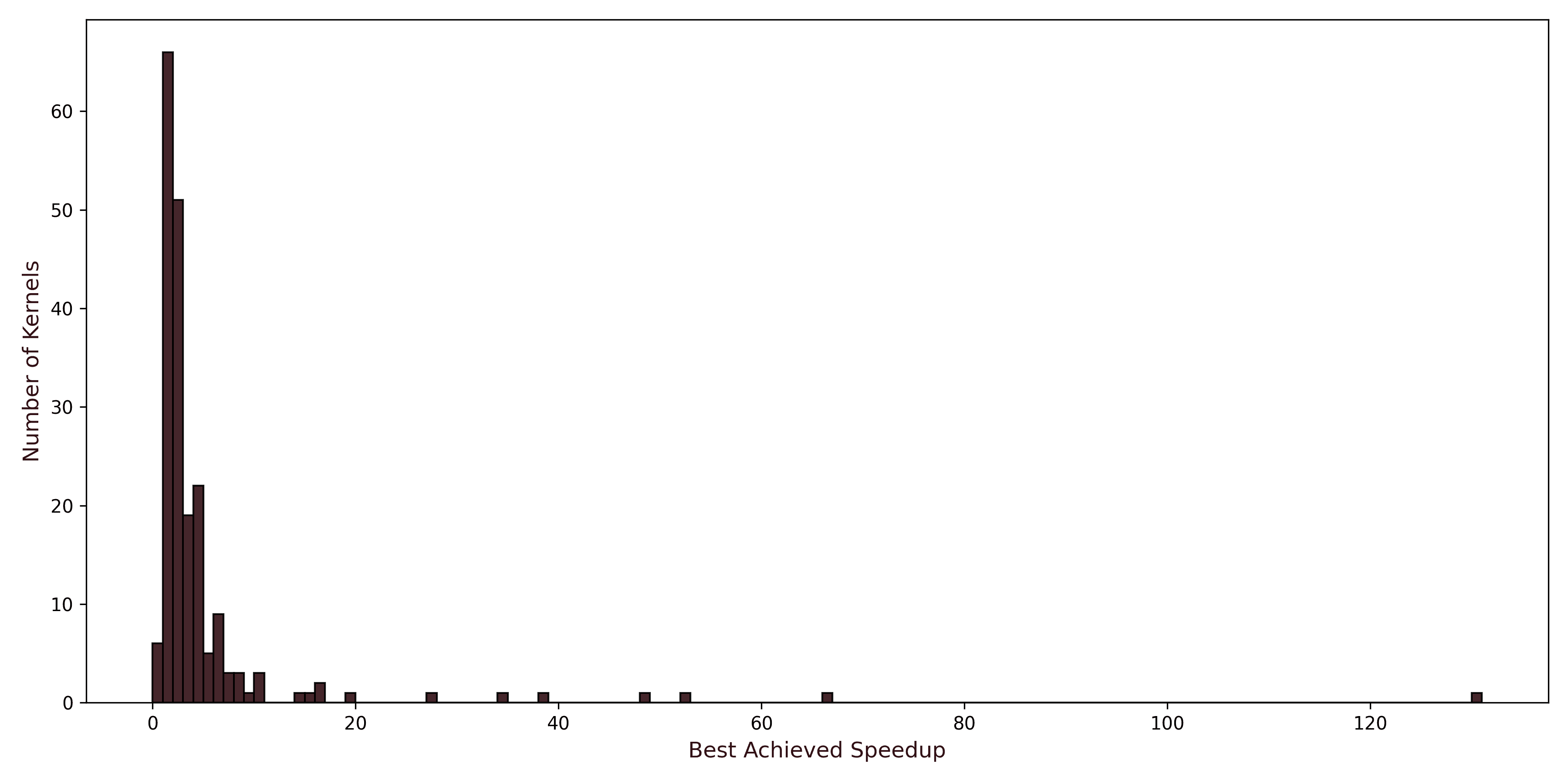
RE-Bench covers frontier AI research problems, such as recovering corrupted models by fixing permuted embeddings, inferring scaling laws that predict optimal model configurations using only small-scale experiments, and implementing architectures under unusual constraints. These tasks demand the ability to form hypotheses, design experiments to test them, interpret surprising results, and build systematically on intermediate discoveries over an extended period of time.
Locus achieves these results through an end-to-end, continuous 64-hour run, scoring 1.30 compared to the human expert baseline¹ of 1.27. The human experts recruited by METR include researchers from frontier AI labs such as OpenAI, Google DeepMind, and Anthropic as well as ML PhD students from top graduate programs such as Stanford University and Carnegie Mellon University. At 2 hours, Locus scores 0.34 versus 0.07 for humans; at 8 hours, 0.70 versus 0.65. Previous AI systems including Claude Code (with Sonnet-4.5) must work in discrete 30 min to 1 hr intervals and show no meaningful improvement beyond 2 hours, plateauing around 0.64 regardless of additional time².
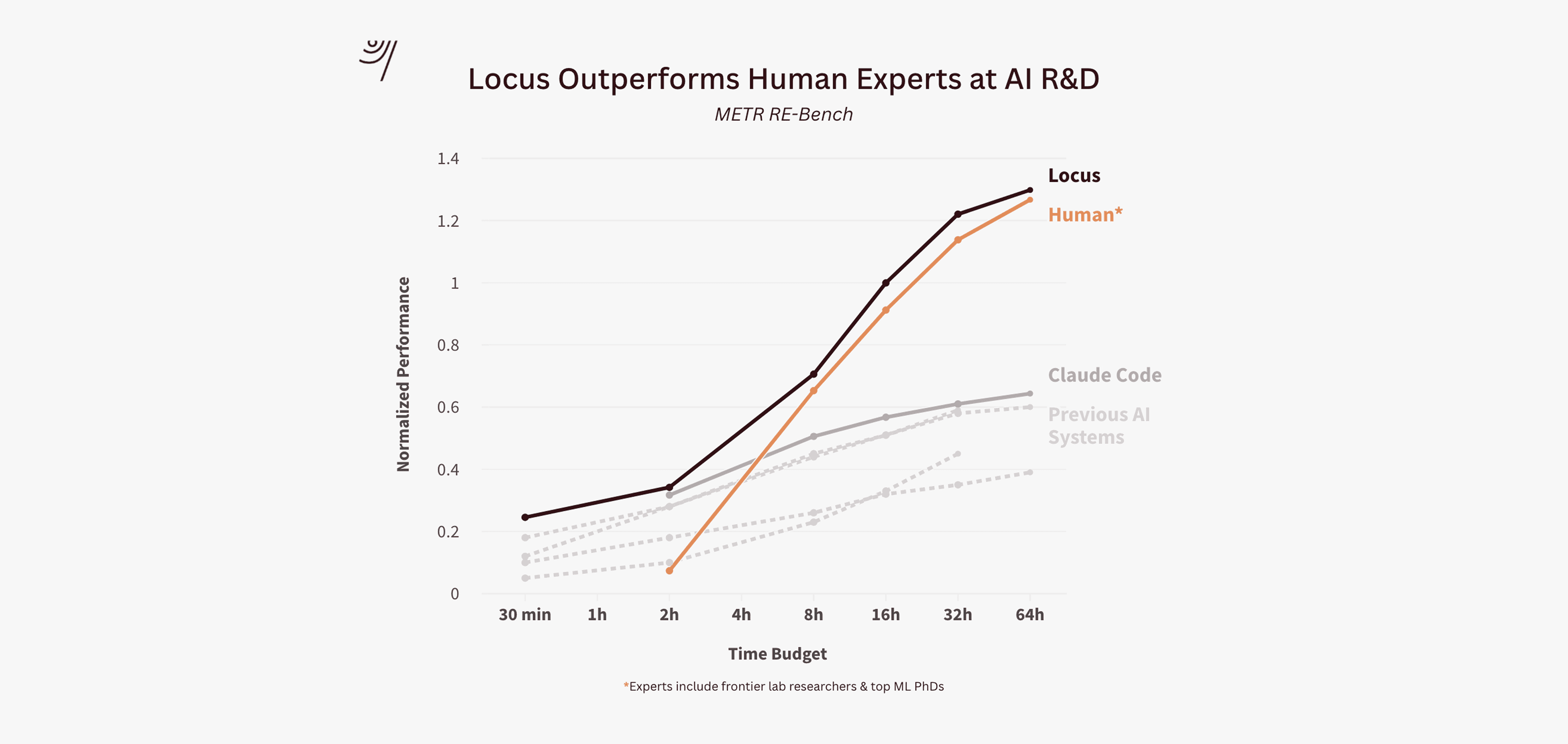
In our evaluations of Locus on kernel optimization we use two established benchmarks for generated CUDA kernels: KernelBench and Robust-KBench. The PyTorch kernels given to Locus in these evaluations range from various fused operations to matmul kernels. Across these different kernel types Locus achieves speedups ranging from 1.5x to over 100x⁴. For example, Locus reaches a 100x speedup on LayerNorm for large parameter counts and a 20x speedup for Llama FFW.
All reported speedup results are median values from 10 runs each with 1000 iterations and 25 warmup steps across 10 separate NVIDIA H100 GPU's using CUDA 12.4. Results were externally reviewed and verified against PyTorch eager execution on NVIDIA H100/H800 GPUs using median timing across multiple runs. Locus displayed significant creativity and engineering ability. In addition to standard approaches such as vectorizing memory access, Locus also employs more advanced optimizations such as utilizing async copy and cooperative groups.
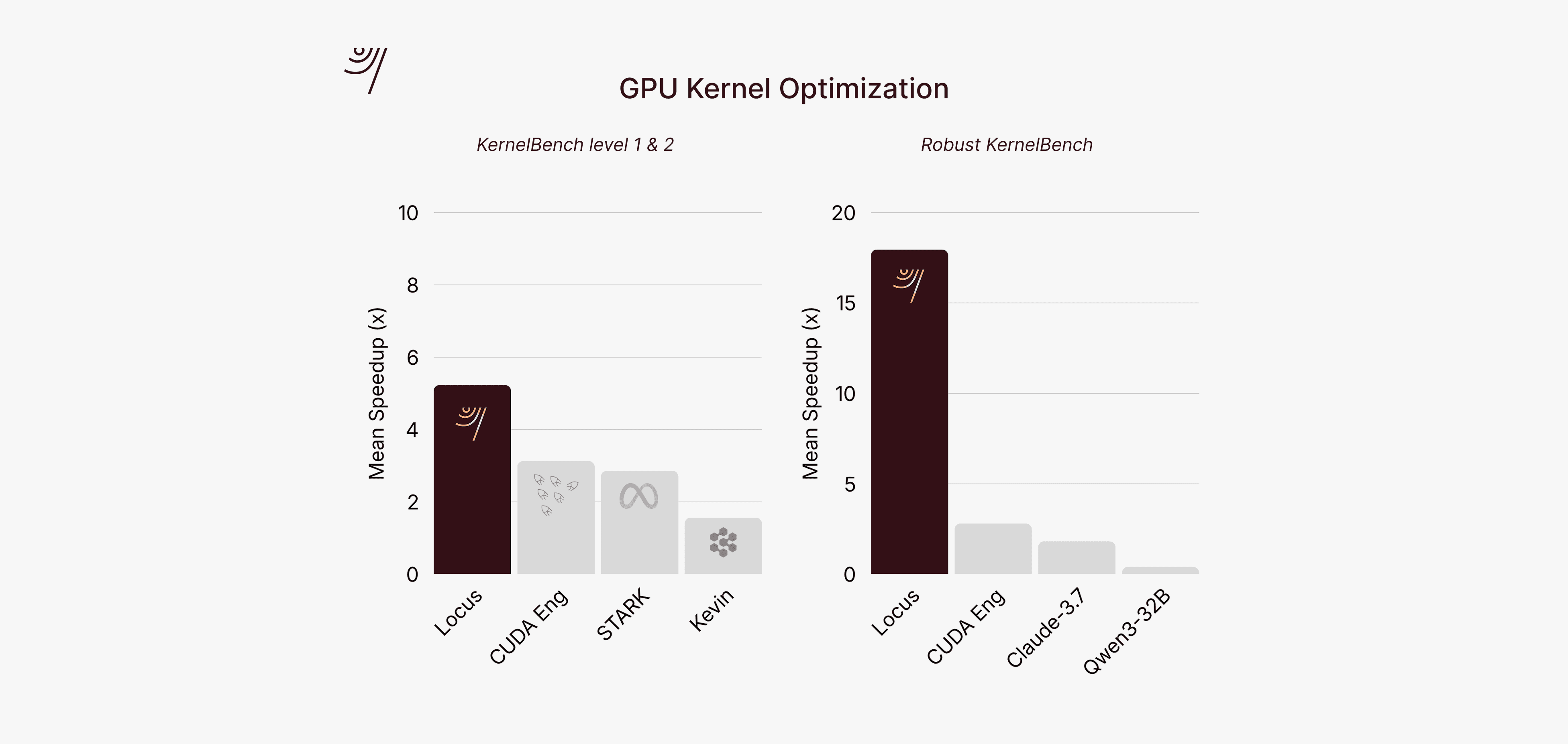
MLE-Bench tests performance on Kaggle competition problems from domains like natural language processing, computer vision, and tabular data prediction³. Each problem requires building a complete machine learning solution: loading and exploring data, engineering features, selecting and training models, and optimizing predictions to maximize competition metrics. In contrast with prior systems specialized for machine learning engineering (68% prior SOTA from Microsoft), Locus earns a medal in 77% of competitions and displays remarkable generalization across domains.
Predictable Scaling
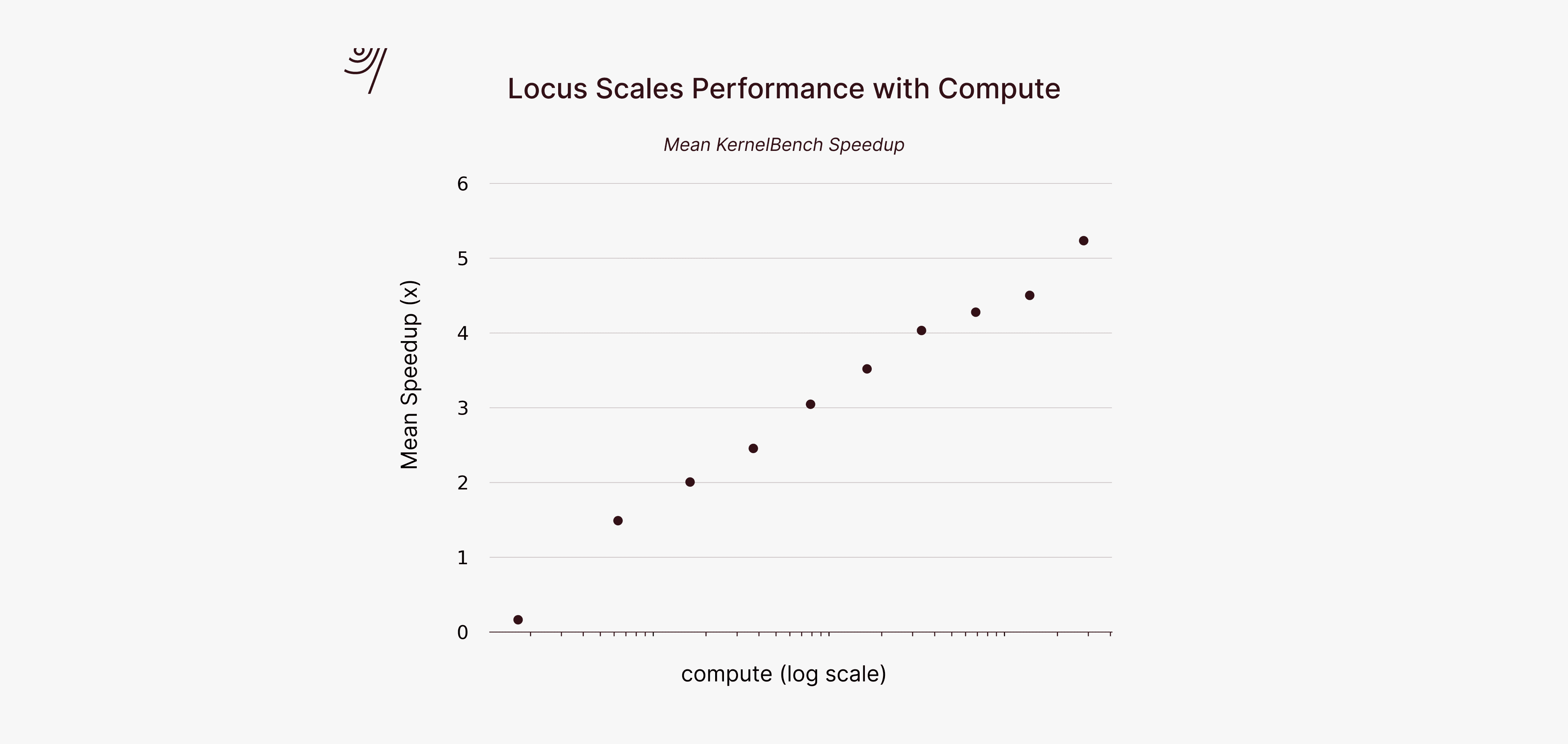
Locus demonstrates predictable performance scaling with compute investment. When we plot performance against compute (measured in log scale), we observe a consistent linear relationship—each order of magnitude of compute yields a reliable improvement in task performance. This scaling behavior holds across all three benchmarks, suggesting we haven't approached diminishing returns. Unlike systems that quickly saturate their performance regardless of additional resources, Locus can effectively utilize several orders of magnitude more compute to achieve proportionally better results.
This predictable scaling has important implications for deployment. Organizations can accurately forecast the compute investment needed to reach specific performance targets, making informed decisions about when performance gains justify additional resources. The consistent scaling also suggests significant headroom—as compute becomes cheaper and more available, these capabilities will naturally extend to more complex problems without requiring fundamental algorithmic breakthroughs. We expect Locus to continue scaling effectively to longer time horizons and harder research problems that are currently out of reach.
Limitations
While these results demonstrate meaningful progress toward recursive self-improvement where AI systems can accelerate AI development, the full transformation of AI progress will only emerge once these capabilities improve. Currently, Locus still operates within existing ML paradigms — it excels at finding better solutions within problem spaces but doesn't yet redefine the problem spaces themselves.
While these results reflect important advancements in enabling AI systems to accelerate components of AI development, today’s capabilities operate within well-understood machine learning frameworks and are optimized for clearly scoped problem settings. The benchmarks we selected — RE-Bench, MLE-Bench, and KernelBench — provide structured objectives and rapid feedback that support reliable evaluation at scale. In contrast, many large-scale research and engineering efforts in production environments involve longer timelines, bespoke success criteria, and integration with distributed infrastructure. Our current evaluations focus on a representative but limited set of tasks, and we are actively expanding held-out evaluations to further ensure alignment with the broader range of real-world research and engineering challenges. This phased approach allows us to deliver measurable, predictable results while continuously strengthening Locus’s capabilities across more complex problem spaces.
Roadmap & Release
Our vision is to transform scientific discovery from sporadic breakthroughs into a continuous, predictable process. Instead of waiting years between major advances, we envision AI systems that can sustain the kind of relentless momentum that drives paradigm shifts — not through individual moments of genius, but through systematic exploration. The results we're sharing today represent an important milestone toward that goal.
A critical step toward this vision is developing AI that can make meaningful contributions to AI research itself. If AI systems can design better architectures, discover more efficient training methods, and optimize their own infrastructure, we unlock a fundamentally different rate of progress. Locus's performance on RE-Bench, MLE-Bench, and KernelBench demonstrates early capabilities in this direction. We're currently deploying Locus internally on several important research problems, and it has already generated novel scientific discoveries that we'll be sharing in the coming months.
We continue to onboard researchers to our Intology beta program, where early users are applying our systems to computational challenges in their domains. We plan to make Locus available for both research and enterprise use, enabling the broader community to leverage these capabilities for their own work.
Acknowledgements
We thank Jintao Zhang from Tsinghua University for reviewing and verifying our kernel results.
Footnotes
¹ We follow the methodology from the official RE-Bench paper to reproduce human expert performance where the time budget is equal to time limit per run x number of attempts. We reviewed the top-performing solutions for cheating and did not identify any evaluation hacking / cheating. Following the human setting, Locus has access to the scoring function during experimentation (with access to only the same artifacts explicitly allowed for humans) except for small scaling laws, but cannot change the evaluation setup or any scoring code. For small scaling laws, the evaluation is run once on Locus’ final result.
² Claude Code (Sonnet 4.5) is evaluated with METR’s methodology for AI agent baselines from the RE-Bench paper, with 1 hour intervals.
³We evaluate on the MLE-Bench Lite subset, consisting of 22 Kaggle competitions.
⁴